---
title: 阿里云函数计算实现OSS上传压缩文件自动解压
description: 利用阿里云Serverless函数实现OSS上传压缩文件(ZIP/RAR/7Z)自动解压
date: 2025-12-24T14:11:00+08:00
slug: oss-unzip
categories:
- 奇技淫巧
tags: [
"前端",
"后端",
"Serverless",
"建站"
]
# lastmod: 2025-02-19T01:43:00+08:00
---
阿里云OSS提供了上传ZIP文件使用函数计算自动解压的实现,但是不支持其他格式,本文介绍如何基于其默认代码模板实现上传RAR/7Z文件自动解压。
首先,在阿里云OSS控制台找到“ZIP包解压”,点击按钮创建一个新的函数:
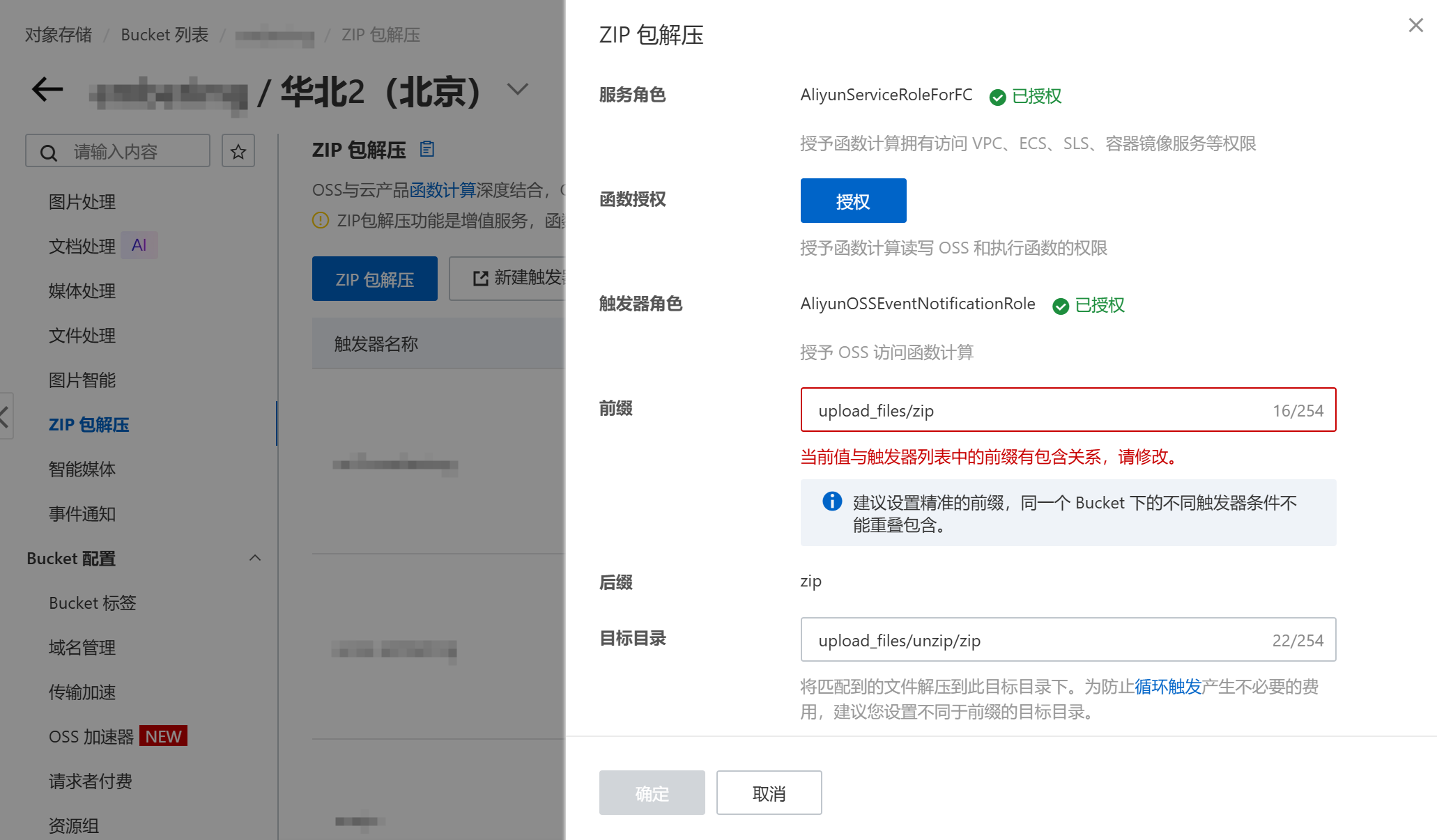 > **注意:** 这里的前缀和目标目录最好不能有父子目录关系,否则如果解压后的文件仍然有压缩包,会导致无限循环解压。创建完成后,进入函数计算控制台,找到该函数。可以看到**已经自动生成**了一个`index.py`和一个`speed.py`文件。`index.py`是函数计算会执行的主文件,`speed.py`是压缩包里面小文件较多时的速度优化方案(这里暂时不管)。
`index.py`内容应该类似于:
```python
# -*- coding: utf-8 -*-
"""
声明:
这个函数针对文件和文件夹命名编码是如下格式:
1. mac/linux 系统, 默认是utf-8
2. windows 系统, 默认是gb2312, 也可以是utf-8
对于其他编码,我们这里尝试使用chardet这个库进行编码判断,但是这个并不能保证100% 正确,
建议用户先调试函数,如果有必要改写这个函数,并保证调试通过
Statement:
This function names and encodes files and folders as follows:
1. MAC/Linux system, default is utf-8
2. For Windows, the default is gb2312 or utf-8
For other encodings, we try to use the chardet library for coding judgment here,
but this is not guaranteed to be 100% correct.
If necessary to rewrite this function, and ensure that the debugging pass
"""
import oss2
import json
import os
import logging
import zipfile
import chardet
# Close the info log printed by the oss SDK
logging.getLogger("oss2.api").setLevel(logging.ERROR)
logging.getLogger("oss2.auth").setLevel(logging.ERROR)
LOGGER = logging.getLogger()
# ...
```
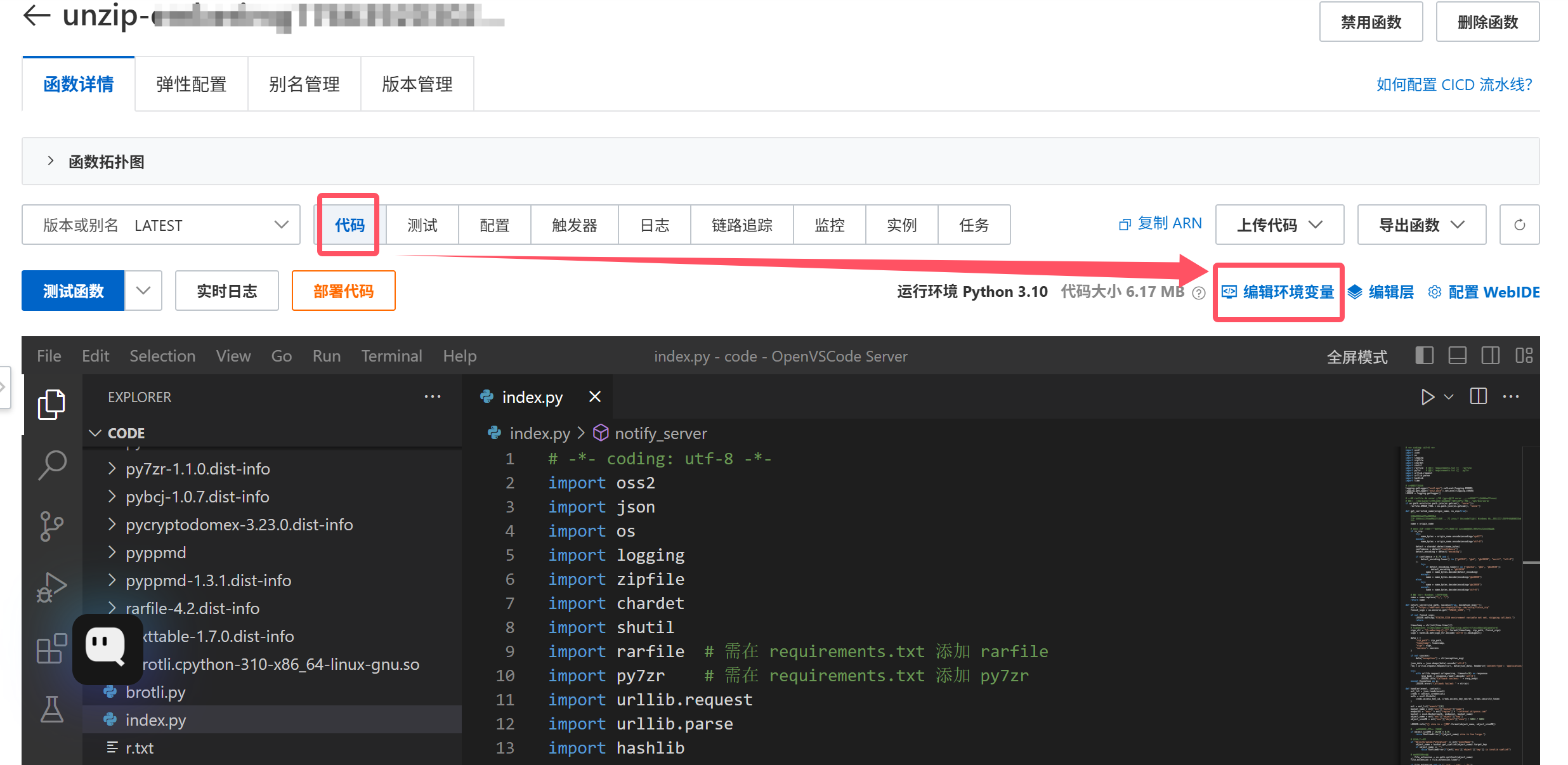
我们点击“编辑环境变量”,可以看到里面目前只有两个环境变量:`PROCESSED_DIR`和`RETAIN_FILE_NAME`,分别代表**ZIP包解压后的目标目录**和**是否将压缩包文件名作为新目录名**(我们刚刚设置的)。
> **注意:** 这里的前缀和目标目录最好不能有父子目录关系,否则如果解压后的文件仍然有压缩包,会导致无限循环解压。创建完成后,进入函数计算控制台,找到该函数。可以看到**已经自动生成**了一个`index.py`和一个`speed.py`文件。`index.py`是函数计算会执行的主文件,`speed.py`是压缩包里面小文件较多时的速度优化方案(这里暂时不管)。
`index.py`内容应该类似于:
```python
# -*- coding: utf-8 -*-
"""
声明:
这个函数针对文件和文件夹命名编码是如下格式:
1. mac/linux 系统, 默认是utf-8
2. windows 系统, 默认是gb2312, 也可以是utf-8
对于其他编码,我们这里尝试使用chardet这个库进行编码判断,但是这个并不能保证100% 正确,
建议用户先调试函数,如果有必要改写这个函数,并保证调试通过
Statement:
This function names and encodes files and folders as follows:
1. MAC/Linux system, default is utf-8
2. For Windows, the default is gb2312 or utf-8
For other encodings, we try to use the chardet library for coding judgment here,
but this is not guaranteed to be 100% correct.
If necessary to rewrite this function, and ensure that the debugging pass
"""
import oss2
import json
import os
import logging
import zipfile
import chardet
# Close the info log printed by the oss SDK
logging.getLogger("oss2.api").setLevel(logging.ERROR)
logging.getLogger("oss2.auth").setLevel(logging.ERROR)
LOGGER = logging.getLogger()
# ...
```
我们点击“编辑环境变量”,可以看到里面目前只有两个环境变量:`PROCESSED_DIR`和`RETAIN_FILE_NAME`,分别代表**ZIP包解压后的目标目录**和**是否将压缩包文件名作为新目录名**(我们刚刚设置的)。
 它们在代码里的位置类似于:
```python
PROCESSED_DIR = os.environ.get("PROCESSED_DIR", "")
RETAIN_FILE_NAME = os.environ.get("RETAIN_FILE_NAME", "")
if RETAIN_FILE_NAME == "false":
newKeyPrefix = PROCESSED_DIR
else:
newKeyPrefix = os.path.join(PROCESSED_DIR, zip_name)
newKeyPrefix = newKeyPrefix.replace(".zip", "/")
# ...
```
为了支持RAR/7Z文件,我们需要添加几个环境变量:`ZIP_DIR`、`RAR_DIR`、`Z_DIR`(环境变量不支持以数字开头),分别代表ZIP/RAR/7Z文件的解压目录。我还额外添加了一个解压成功回调应用服务器的签名private key。配置完成后点击部署。
它们在代码里的位置类似于:
```python
PROCESSED_DIR = os.environ.get("PROCESSED_DIR", "")
RETAIN_FILE_NAME = os.environ.get("RETAIN_FILE_NAME", "")
if RETAIN_FILE_NAME == "false":
newKeyPrefix = PROCESSED_DIR
else:
newKeyPrefix = os.path.join(PROCESSED_DIR, zip_name)
newKeyPrefix = newKeyPrefix.replace(".zip", "/")
# ...
```
为了支持RAR/7Z文件,我们需要添加几个环境变量:`ZIP_DIR`、`RAR_DIR`、`Z_DIR`(环境变量不支持以数字开头),分别代表ZIP/RAR/7Z文件的解压目录。我还额外添加了一个解压成功回调应用服务器的签名private key。配置完成后点击部署。
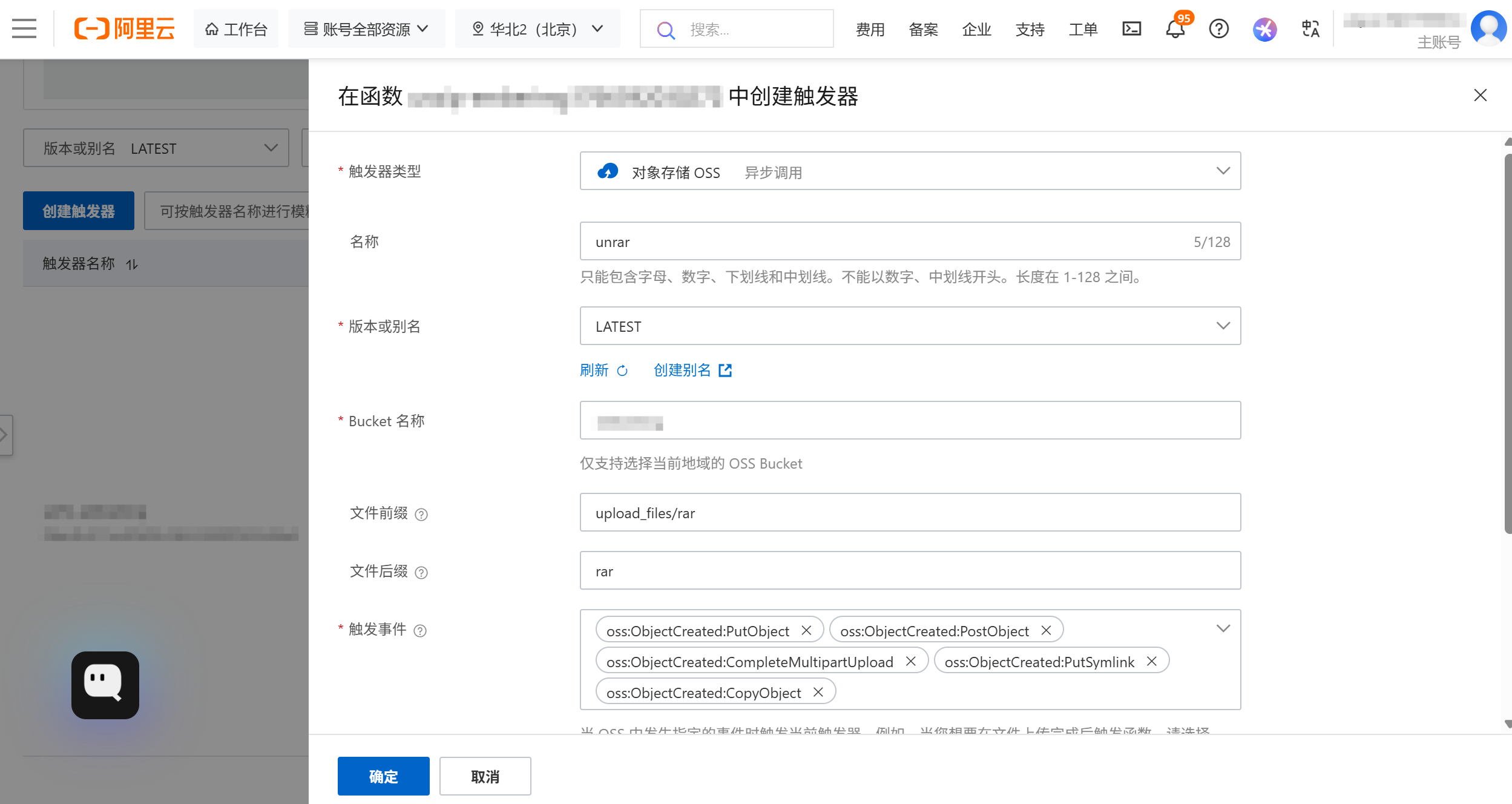
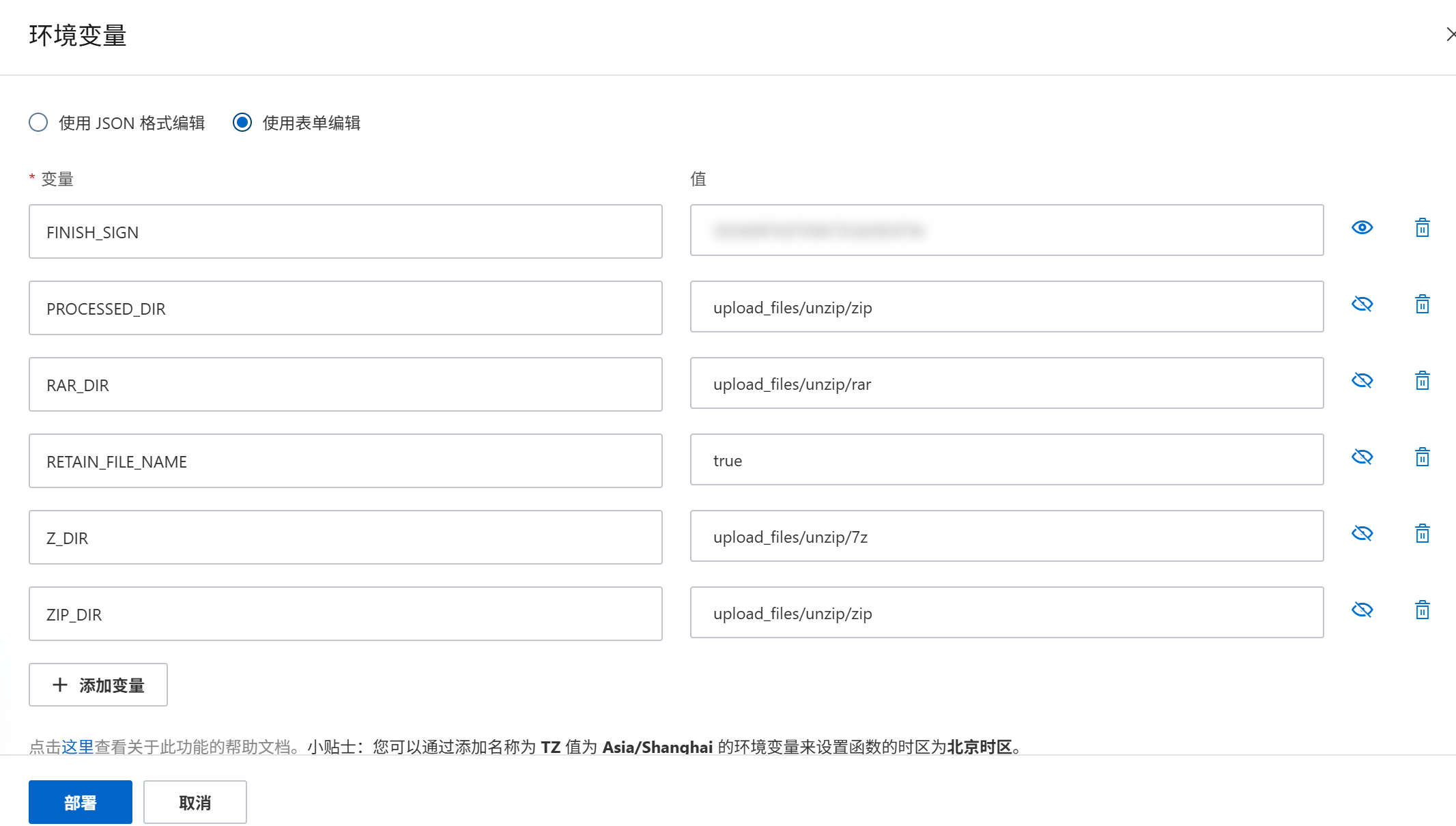 然后打开触发器选项,新建触发器,分别添加RAR和7Z文件的触发器。这里以RAR为例,仿照ZIP的参数,设置RAR文件的前缀和后缀(rar)。注意这里“触发事件”默认**不包含`CopyObject`事件**,如果希望复制压缩包也触发解压,需要手动添加此事件。
然后打开触发器选项,新建触发器,分别添加RAR和7Z文件的触发器。这里以RAR为例,仿照ZIP的参数,设置RAR文件的前缀和后缀(rar)。注意这里“触发事件”默认**不包含`CopyObject`事件**,如果希望复制压缩包也触发解压,需要手动添加此事件。
 配置完触发器后,我们再更改`index.py`代码,添加对RAR/7Z文件的解压逻辑。注意,我们要安装两个额外的库:`rarfile`和`py7zr`。首先,我们在Web VSCode里面`index.py`目录下新建一个`r.txt`:
```
rarfile
py7zr
```
然后按Ctrl+\`激活Web VSCode终端,输入`pip3 install -t . -r r.txt`安装这些库到**当前目录**(非常重要)。由于`rarfile`包底层需要调用`unrar`命令,所以我们还需要安装Linux的`unrar`命令。在终端使用`wget`:
```
wget https://www.rarlab.com/rar/rarlinux-x64-712.tar.gz
```
如果这个链接失效,可以在[这里](https://www.rarlab.com/download.htm)查看最新版本对应下载链接。然后解压并移动`unrar`到当前目录,并赋予执行权限:
```
tar -zxvf rarlinux-x64-712.tar.gz
mv rar/unrar .
chmod +x unrar
rm -rf rar rarlinux-x64-712.tar.gz
```
现在Web VSCode文件管理器左侧目录里应该有:index.py、unrar 文件、以及一大堆 py7zr 等文件夹。然后我们开始写`index.py`的代码。这是我的代码,复用了模板中对文件名的编码修正(**这个非常重要**,实测没修正解压出来会有很多乱码),并且实现了解压成功或失败都回调应用服务器的逻辑。
```python
# -*- coding: utf-8 -*-
import oss2
import json
import os
import logging
import zipfile
import chardet
import shutil
import rarfile
import py7zr
import urllib.request
import urllib.parse
import hashlib
import time
# 设置日志级别
logging.getLogger("oss2.api").setLevel(logging.ERROR)
logging.getLogger("oss2.auth").setLevel(logging.ERROR)
LOGGER = logging.getLogger()
# 配置 rarfile 的 unrar 路径 (我们已经把 unrar 二进制文件放在了代码根目录)
if os.path.exists(os.path.join(os.getcwd(), "unrar")):
rarfile.UNRAR_TOOL = os.path.join(os.getcwd(), "unrar")
def get_corrected_name(origin_name):
"""
处理文件名编码问题。
ZIP 文件常有编码问题,RAR 和 7Z 通常是 Unicode,但在 Windows 下也可能有路径分隔符问题。
这里统一尝试修复编码,以防万一。
"""
name = origin_name
# 尝试复杂的编码猜测
try:
# 许多乱码是因为 ZIP 默认用 cp437 读取了 GBK/UTF-8
name_bytes = origin_name.encode(encoding="cp437")
except:
name_bytes = origin_name.encode(encoding="utf-8")
detect = chardet.detect(name_bytes)
confidence = detect["confidence"]
detect_encoding = detect["encoding"]
if confidence > 0.75 and (
detect_encoding.lower() in ["gb2312", "gbk", "gb18030", "ascii", "utf-8"]
):
try:
if detect_encoding.lower() in ["gb2312", "gbk", "gb18030"]:
detect_encoding = "gb18030"
name = name_bytes.decode(detect_encoding)
except:
name = name_bytes.decode(encoding="gb18030")
else:
try:
name = name_bytes.decode(encoding="gb18030")
except:
name = name_bytes.decode(encoding="utf-8")
# 统一修复 Windows 路径分隔符
name = name.replace("\\", "/")
return name
def notify_server(zip_path, success=True, exception_msg=""):
# 自行实现回调服务器的逻辑,这里不展示
def handler(event, context):
evt_lst = json.loads(event)
creds = context.credentials
auth = oss2.StsAuth(
creds.access_key_id, creds.access_key_secret, creds.security_token
)
evt = evt_lst["events"][0]
bucket_name = evt["oss"]["bucket"]["name"]
endpoint = "oss-" + evt["region"] + "-internal.aliyuncs.com"
bucket = oss2.Bucket(auth, endpoint, bucket_name)
object_name = evt["oss"]["object"]["key"]
object_sizeMB = evt["oss"]["object"]["size"] / 1024 / 1024
LOGGER.info("{} size is = {}MB".format(object_name, object_sizeMB))
# 检查文件大小限制 (10GB)
if object_sizeMB > 10240 * 0.9:
raise RuntimeError(f"{object_name} size is too large.")
# 处理软链接
if "ObjectCreated:PutSymlink" == evt["eventName"]:
object_name = bucket.get_symlink(object_name).target_key
if object_name == "":
raise RuntimeError(f"{evt['oss']['object']['key']} is invalid symlink")
# 获取文件后缀
_, file_extension = os.path.splitext(object_name)
file_extension = file_extension.lower()
if file_extension not in ['.zip', '.rar', '.7z']:
raise RuntimeError(f"{object_name} filetype is not supported (zip/rar/7z)")
LOGGER.info(f"start to decompress {file_extension} file = {object_name}")
# --- 配置不同类型的环境变量 ---
# 根据后缀选择对应的环境变量,如果没配则默认为空
if file_extension == '.zip':
target_dir_root = os.environ.get("ZIP_DIR", "")
elif file_extension == '.rar':
target_dir_root = os.environ.get("RAR_DIR", "")
elif file_extension == '.7z':
target_dir_root = os.environ.get("Z_DIR", "")
# 获取文件名(不含路径)
archive_name = os.path.basename(object_name)
# 是否保留文件夹结构
RETAIN_FILE_NAME = os.environ.get("RETAIN_FILE_NAME", "")
if RETAIN_FILE_NAME == "false":
newKeyPrefix = target_dir_root
else:
newKeyPrefix = os.path.join(target_dir_root, archive_name)
# 确保前缀以 / 结尾(如果非空)
if newKeyPrefix and not newKeyPrefix.endswith('/'):
newKeyPrefix += '/'
# 移除后缀名部分作为目录 (例如 xxx.zip -> xxx/)
# 注意:这里可能会导致重复斜杠,如果 newKeyPrefix 已经是 '.../zip/' 且 file_extension 是 '.zip'
# 替换后可能变成 '.../zip//'
# 我们改用 splitext 来处理,更稳健
if RETAIN_FILE_NAME != "false":
# 如果是保留文件夹结构,我们希望把文件名作为目录
# newKeyPrefix 现在是 "root_dir/filename.ext/"
# 我们想把它变成 "root_dir/filename/"
if newKeyPrefix.endswith('/'):
newKeyPrefix = newKeyPrefix[:-1] # 去掉末尾斜杠以便处理后缀
if newKeyPrefix.lower().endswith(file_extension):
newKeyPrefix = newKeyPrefix[:-len(file_extension)]
newKeyPrefix += '/'
# 准备临时目录
tmpWorkDir = "/tmp/{}".format(context.request_id)
if not os.path.exists(tmpWorkDir):
os.makedirs(tmpWorkDir)
local_archive_path = os.path.join(tmpWorkDir, archive_name)
bucket.get_object_to_file(object_name, local_archive_path)
try:
# === ZIP 处理逻辑 ===
if file_extension == '.zip':
with zipfile.ZipFile(local_archive_path) as zip_ref:
for file_info in zip_ref.infolist():
if file_info.is_dir():
continue
process_and_upload(
bucket, zip_ref, file_info.filename, file_info.file_size,
tmpWorkDir, newKeyPrefix, object_sizeMB
)
# === RAR 处理逻辑 ===
elif file_extension == '.rar':
# rarfile 需要系统安装 unrar
with rarfile.RarFile(local_archive_path) as rar_ref:
for file_info in rar_ref.infolist():
if file_info.isdir():
continue
process_and_upload(
bucket, rar_ref, file_info.filename, file_info.file_size,
tmpWorkDir, newKeyPrefix, object_sizeMB
)
# === 7Z 处理逻辑 ===
elif file_extension == '.7z':
with py7zr.SevenZipFile(local_archive_path, mode='r') as z_ref:
# py7zr 获取文件列表的方式略有不同
for file_info in z_ref.list():
if file_info.is_directory:
continue
# 检查大小
if object_sizeMB + file_info.uncompressed / 1024 / 1024 > 10240 * 0.99:
LOGGER.error(f"{file_info.filename} skipped (disk full risk)")
continue
z_ref.extract(targets=[file_info.filename], path=tmpWorkDir)
# 上传逻辑
upload_file(bucket, file_info.filename, tmpWorkDir, newKeyPrefix)
# Callback to server
notify_server(object_name, success=True)
except Exception as e:
LOGGER.error(f"Decompression failed: {e}")
notify_server(object_name, success=False, exception_msg=e)
raise e
finally:
# 清理临时目录
if os.path.exists(tmpWorkDir):
shutil.rmtree(tmpWorkDir)
def process_and_upload(bucket, archive_ref, filename, file_size, tmp_dir, prefix, total_zip_size):
"""
辅助函数:用于 ZIP 和 RAR 的解压上传(因为它们的接口相似)
"""
if total_zip_size + file_size / 1024 / 1024 > 10240 * 0.99:
LOGGER.error(f"{filename} skipped due to size limit")
return
# 解压单个文件
archive_ref.extract(filename, tmp_dir)
upload_file(bucket, filename, tmp_dir, prefix)
def upload_file(bucket, original_filename, tmp_dir, prefix):
"""
辅助函数:处理路径、重命名并上传
"""
local_file_path = os.path.join(tmp_dir, original_filename)
# 修正文件名(处理乱码和路径分隔符)
corrected_name = get_corrected_name(original_filename)
# 拼接 OSS Key
new_oss_key = os.path.join(prefix, corrected_name).replace("\\", "/")
LOGGER.info(f"uploading {original_filename} to {new_oss_key}")
bucket.put_object_from_file(new_oss_key, local_file_path)
# 上传后立即删除本地文件以释放空间
if os.path.exists(local_file_path):
os.remove(local_file_path)
```
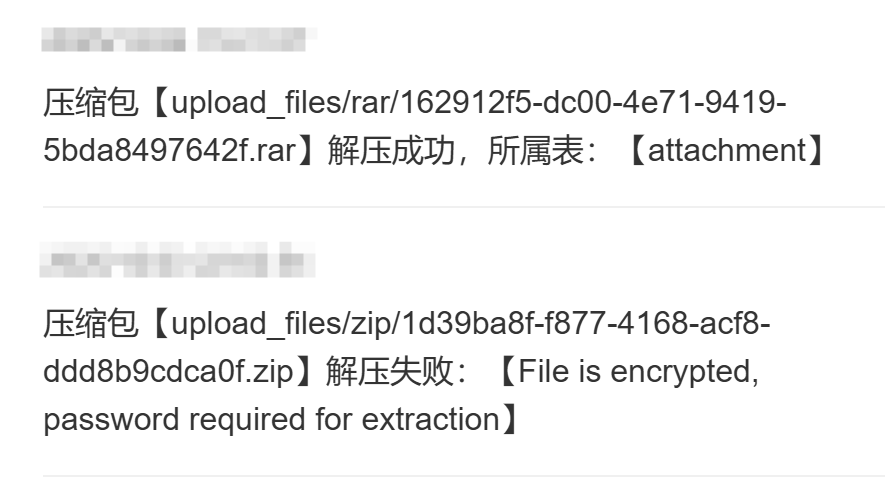
写完代码记得点击 **【部署代码】** 。然后实测可以正确解压并通知到应用服务器,解压失败也能通知到应用服务器(OSS触发器默认会重试3次):
配置完触发器后,我们再更改`index.py`代码,添加对RAR/7Z文件的解压逻辑。注意,我们要安装两个额外的库:`rarfile`和`py7zr`。首先,我们在Web VSCode里面`index.py`目录下新建一个`r.txt`:
```
rarfile
py7zr
```
然后按Ctrl+\`激活Web VSCode终端,输入`pip3 install -t . -r r.txt`安装这些库到**当前目录**(非常重要)。由于`rarfile`包底层需要调用`unrar`命令,所以我们还需要安装Linux的`unrar`命令。在终端使用`wget`:
```
wget https://www.rarlab.com/rar/rarlinux-x64-712.tar.gz
```
如果这个链接失效,可以在[这里](https://www.rarlab.com/download.htm)查看最新版本对应下载链接。然后解压并移动`unrar`到当前目录,并赋予执行权限:
```
tar -zxvf rarlinux-x64-712.tar.gz
mv rar/unrar .
chmod +x unrar
rm -rf rar rarlinux-x64-712.tar.gz
```
现在Web VSCode文件管理器左侧目录里应该有:index.py、unrar 文件、以及一大堆 py7zr 等文件夹。然后我们开始写`index.py`的代码。这是我的代码,复用了模板中对文件名的编码修正(**这个非常重要**,实测没修正解压出来会有很多乱码),并且实现了解压成功或失败都回调应用服务器的逻辑。
```python
# -*- coding: utf-8 -*-
import oss2
import json
import os
import logging
import zipfile
import chardet
import shutil
import rarfile
import py7zr
import urllib.request
import urllib.parse
import hashlib
import time
# 设置日志级别
logging.getLogger("oss2.api").setLevel(logging.ERROR)
logging.getLogger("oss2.auth").setLevel(logging.ERROR)
LOGGER = logging.getLogger()
# 配置 rarfile 的 unrar 路径 (我们已经把 unrar 二进制文件放在了代码根目录)
if os.path.exists(os.path.join(os.getcwd(), "unrar")):
rarfile.UNRAR_TOOL = os.path.join(os.getcwd(), "unrar")
def get_corrected_name(origin_name):
"""
处理文件名编码问题。
ZIP 文件常有编码问题,RAR 和 7Z 通常是 Unicode,但在 Windows 下也可能有路径分隔符问题。
这里统一尝试修复编码,以防万一。
"""
name = origin_name
# 尝试复杂的编码猜测
try:
# 许多乱码是因为 ZIP 默认用 cp437 读取了 GBK/UTF-8
name_bytes = origin_name.encode(encoding="cp437")
except:
name_bytes = origin_name.encode(encoding="utf-8")
detect = chardet.detect(name_bytes)
confidence = detect["confidence"]
detect_encoding = detect["encoding"]
if confidence > 0.75 and (
detect_encoding.lower() in ["gb2312", "gbk", "gb18030", "ascii", "utf-8"]
):
try:
if detect_encoding.lower() in ["gb2312", "gbk", "gb18030"]:
detect_encoding = "gb18030"
name = name_bytes.decode(detect_encoding)
except:
name = name_bytes.decode(encoding="gb18030")
else:
try:
name = name_bytes.decode(encoding="gb18030")
except:
name = name_bytes.decode(encoding="utf-8")
# 统一修复 Windows 路径分隔符
name = name.replace("\\", "/")
return name
def notify_server(zip_path, success=True, exception_msg=""):
# 自行实现回调服务器的逻辑,这里不展示
def handler(event, context):
evt_lst = json.loads(event)
creds = context.credentials
auth = oss2.StsAuth(
creds.access_key_id, creds.access_key_secret, creds.security_token
)
evt = evt_lst["events"][0]
bucket_name = evt["oss"]["bucket"]["name"]
endpoint = "oss-" + evt["region"] + "-internal.aliyuncs.com"
bucket = oss2.Bucket(auth, endpoint, bucket_name)
object_name = evt["oss"]["object"]["key"]
object_sizeMB = evt["oss"]["object"]["size"] / 1024 / 1024
LOGGER.info("{} size is = {}MB".format(object_name, object_sizeMB))
# 检查文件大小限制 (10GB)
if object_sizeMB > 10240 * 0.9:
raise RuntimeError(f"{object_name} size is too large.")
# 处理软链接
if "ObjectCreated:PutSymlink" == evt["eventName"]:
object_name = bucket.get_symlink(object_name).target_key
if object_name == "":
raise RuntimeError(f"{evt['oss']['object']['key']} is invalid symlink")
# 获取文件后缀
_, file_extension = os.path.splitext(object_name)
file_extension = file_extension.lower()
if file_extension not in ['.zip', '.rar', '.7z']:
raise RuntimeError(f"{object_name} filetype is not supported (zip/rar/7z)")
LOGGER.info(f"start to decompress {file_extension} file = {object_name}")
# --- 配置不同类型的环境变量 ---
# 根据后缀选择对应的环境变量,如果没配则默认为空
if file_extension == '.zip':
target_dir_root = os.environ.get("ZIP_DIR", "")
elif file_extension == '.rar':
target_dir_root = os.environ.get("RAR_DIR", "")
elif file_extension == '.7z':
target_dir_root = os.environ.get("Z_DIR", "")
# 获取文件名(不含路径)
archive_name = os.path.basename(object_name)
# 是否保留文件夹结构
RETAIN_FILE_NAME = os.environ.get("RETAIN_FILE_NAME", "")
if RETAIN_FILE_NAME == "false":
newKeyPrefix = target_dir_root
else:
newKeyPrefix = os.path.join(target_dir_root, archive_name)
# 确保前缀以 / 结尾(如果非空)
if newKeyPrefix and not newKeyPrefix.endswith('/'):
newKeyPrefix += '/'
# 移除后缀名部分作为目录 (例如 xxx.zip -> xxx/)
# 注意:这里可能会导致重复斜杠,如果 newKeyPrefix 已经是 '.../zip/' 且 file_extension 是 '.zip'
# 替换后可能变成 '.../zip//'
# 我们改用 splitext 来处理,更稳健
if RETAIN_FILE_NAME != "false":
# 如果是保留文件夹结构,我们希望把文件名作为目录
# newKeyPrefix 现在是 "root_dir/filename.ext/"
# 我们想把它变成 "root_dir/filename/"
if newKeyPrefix.endswith('/'):
newKeyPrefix = newKeyPrefix[:-1] # 去掉末尾斜杠以便处理后缀
if newKeyPrefix.lower().endswith(file_extension):
newKeyPrefix = newKeyPrefix[:-len(file_extension)]
newKeyPrefix += '/'
# 准备临时目录
tmpWorkDir = "/tmp/{}".format(context.request_id)
if not os.path.exists(tmpWorkDir):
os.makedirs(tmpWorkDir)
local_archive_path = os.path.join(tmpWorkDir, archive_name)
bucket.get_object_to_file(object_name, local_archive_path)
try:
# === ZIP 处理逻辑 ===
if file_extension == '.zip':
with zipfile.ZipFile(local_archive_path) as zip_ref:
for file_info in zip_ref.infolist():
if file_info.is_dir():
continue
process_and_upload(
bucket, zip_ref, file_info.filename, file_info.file_size,
tmpWorkDir, newKeyPrefix, object_sizeMB
)
# === RAR 处理逻辑 ===
elif file_extension == '.rar':
# rarfile 需要系统安装 unrar
with rarfile.RarFile(local_archive_path) as rar_ref:
for file_info in rar_ref.infolist():
if file_info.isdir():
continue
process_and_upload(
bucket, rar_ref, file_info.filename, file_info.file_size,
tmpWorkDir, newKeyPrefix, object_sizeMB
)
# === 7Z 处理逻辑 ===
elif file_extension == '.7z':
with py7zr.SevenZipFile(local_archive_path, mode='r') as z_ref:
# py7zr 获取文件列表的方式略有不同
for file_info in z_ref.list():
if file_info.is_directory:
continue
# 检查大小
if object_sizeMB + file_info.uncompressed / 1024 / 1024 > 10240 * 0.99:
LOGGER.error(f"{file_info.filename} skipped (disk full risk)")
continue
z_ref.extract(targets=[file_info.filename], path=tmpWorkDir)
# 上传逻辑
upload_file(bucket, file_info.filename, tmpWorkDir, newKeyPrefix)
# Callback to server
notify_server(object_name, success=True)
except Exception as e:
LOGGER.error(f"Decompression failed: {e}")
notify_server(object_name, success=False, exception_msg=e)
raise e
finally:
# 清理临时目录
if os.path.exists(tmpWorkDir):
shutil.rmtree(tmpWorkDir)
def process_and_upload(bucket, archive_ref, filename, file_size, tmp_dir, prefix, total_zip_size):
"""
辅助函数:用于 ZIP 和 RAR 的解压上传(因为它们的接口相似)
"""
if total_zip_size + file_size / 1024 / 1024 > 10240 * 0.99:
LOGGER.error(f"{filename} skipped due to size limit")
return
# 解压单个文件
archive_ref.extract(filename, tmp_dir)
upload_file(bucket, filename, tmp_dir, prefix)
def upload_file(bucket, original_filename, tmp_dir, prefix):
"""
辅助函数:处理路径、重命名并上传
"""
local_file_path = os.path.join(tmp_dir, original_filename)
# 修正文件名(处理乱码和路径分隔符)
corrected_name = get_corrected_name(original_filename)
# 拼接 OSS Key
new_oss_key = os.path.join(prefix, corrected_name).replace("\\", "/")
LOGGER.info(f"uploading {original_filename} to {new_oss_key}")
bucket.put_object_from_file(new_oss_key, local_file_path)
# 上传后立即删除本地文件以释放空间
if os.path.exists(local_file_path):
os.remove(local_file_path)
```
写完代码记得点击 **【部署代码】** 。然后实测可以正确解压并通知到应用服务器,解压失败也能通知到应用服务器(OSS触发器默认会重试3次):